Thursday, 7. August 2008
NAT-Router frisst Zufall
Damit sich da kein anderer als mein "offizielle" Nameserver und die zuständigen Nameserver für ".de" und "google.de" einmischen, wird eine Zufallszahl zusammen mit der Anfrage losgeschickt und nur Antworten als "echt" gewertet, die auch diese Zufallszahl wieder zurückliefern. Ein Angreifer, der keine Ahnung von meinem Zufallsgenerator hat, wird also keine korrekte Antwort liefern können und mir nicht heimlich seine Homepage (oder Mailserver oder Nameserver ...) unterjubeln können.
So dachte man sich das zumindest bisher. Inzwischen weiss man, dass die Zufallszahlen nicht reichen. Zumindest nicht, wenn man das Opfer (oder seine Mitnutzer des gleichen Nameservers) dazu bringen kann, ganz viele Anfragen zu erzeugen. Zum Beispiel, indem man den Mitnutzern ein paar Trojaner installiert. Weil der Begriff "Mitnutzer des Nameservers" zum Beispiel alle Kunden von T-Online umfasst, ist diese Lücke ziemlich schlimm und zwingt vor allem grosse Provider zum schnellen Handeln. Ausserdem wäre es natürlich für einen Angreifer so richtig toll, z.B. sämtliche AOL-Kunden statt zu eBay auf seinen Server zu lenken, entsprechend hoch ist seine Motivation und entsprechend eifrig haben die grossen Provider auch schon schnell gepatcht.
Bei diesen Patchen hat man einfach noch ein bisschen mehr Zufälligkeit dazugebastelt. Statt nur der Zufallszahl wird nun zusätzlich der Quellport der Anfragen durchgewechselt. Der Angreifer muss also Zufallszahl und den passenden unter den 64512 möglichen Quellports rausbekommen.
Auf dem Server haut das auch ganz gut hin. Wenn ich die Quellports paarweise aufmale, sieht die Verteilung schön wolkig und recht zufällig aus. Dass die Verteilung auch echten statistischen Tests standhält, glaube ich jetzt einfach mal.

Quellports der DNS-Anfragen auf dem Server
Auf meinem Client zuhause sieht das irgendwie nicht mehr so toll aus. Mein Rechner verteilt die Anfragen zwar ganz brav und zufällig über 32000 Ports (warum nicht 64000, weiss ich nicht), aber mein Router macht die ganze schöne Verwürfelung wieder kaputt und reduziert die Wolke auf gerade mal 1000 Ports.

Quellports der DNS-Anfragen vor und hinter dem NAT-Router
Der Grund dafür ist schon klar: Ich verwende nicht den eingebauten DNS-Server des Routers, sondern in der Regel den meines Providers. Zu dem vermittelt der Router die Pakete mittels NAT, das heisst, er muss alle Verbindungen von der privaten IP-Adresse meines Rechners zum Server unter seiner eigenen externen IP-Adresse nochmal selbst aufmachen. Und sich dazu noch merken, an welchen internen Rechner und an welchen Port er das Paket zurückschicken muss. Bei sowas denkt der Programmierer an Tabellen und geordnete Strukturen, "Zufälligkeit" war dort nie verlangt und wurde auch nicht eingebaut. Mich wundert, dass der Router die Ports nicht einfach hochzählt.
Das ist kein Grund zu grosser Besorgnis, für einen einzelnen Client werden 1000 Verwürfelungen schon reichen, vermutlich gut unterrichteten Kreisen zufolge würfelt auch T-Online nur mit 2000 Ports. Ausserdem macht das Nutzen der Lücke ja erst so richtig Spass, wenn man ein ganzes Botnetz bei einem Provider betreibt, damit man die Angriffe auch ein bisschen streuen kann. Es hilft ja nichts, z.B. mir falsche Einträge für Citybank, EBay und hotmail unterzujubeln, weil ich mit denen garnichts zu tun habe.
Ich finds aber schon bemerkenswert, dass die Rolle der Router bei der Quellportvergabe nie so richtig gewürdigt wird. Zumindest wenn man Heimanwendern die Notwendigkeit der Patcherei erklären will, sollte man freundlicherweise dazusagen, dass sie sich die Mühe auf den Rechnern auch sparen können, wenn ihr Router das wieder kaputtmacht. Ich denke so ein Router wie meiner (sitecom WL-173) ist der Normalfall in den Wohnzimmern und nicht jeder dieser Router wird wenigstens 1000 Quellports verwenden.
Sunday, 3. August 2008
Openstreetmap API gefunden
Für Offroad-Tracks ist OSM vermutlich noch nicht so gut geeignet, dafür fehlen einfach zu viele Kartendetails und das Satellitenbild bei Google ist schon auch schön. Für eine Spielerei wie die Anzeige der letzten Homepagebesucher langt die freie Karte aber allemal. Und wer mehr Details sehen mag, soll sie halt selbst eintragen...
Ich glaube zwar, dass die Anwender meines Counters das nicht unbedingt zu schätzen wissen. 80% davon sind Kinder, die sich alles in die Homepage kleben, was blinkt. Aber auch denen ist geholfen, wenn sie die erzeugten Bilder anschliessend völlig frei verwenden können und nicht über Googles Nutzungsbedingungen und die Hürden des Urheberrechts stolpern.
Die einzige Nutzungsbedingung ist nämlich, dass man auf das Bild schreibt, dass die Daten von Openstreetmap kommen und anderen Leuten wiederum erlaubt, dieses Bild weiterzuverwenden. Das ist nichtmal für mich eine Einschränkung, ich könnte sogar Geld für den Service verlangen, darf dann nur nicht anderen Leuten verbieten, die Bilder weiterzuverschenken.
Nachtrag 14.8.: Ich habs mal in den Counter als Alternative eingebaut. Die Funktionalität ist die gleiche wie bei den Google-Maps, aber so richtig glücklich bin ich damit noch nicht. Kleinere Fehler bei der Bedienung sind schon noch drin. Mal sehn, ob ich da noch tiefer eindringen will, spannend ist die Sache jedenfalls schon...

(Bild: OpenStreetMap, kopieren erlaubt)
Thursday, 15. May 2008
Grosser Schlüsselbund
Inzwischen gibts auch schon Leute, die ihre Rechner über Nacht damit beschäftigt haben, sämtliche möglichen Schlüsselpaare zu berechnen. Ist auch nicht so schwer, sind ja nur 32000 Stück (!) bei bekannter Schlüssegrösse.
Bisher hiess es ja immer "Passwort-Authentifikation ist zu leicht mit Ausprobieren zu knacken, also nimm ein private-public-key-Verfahren, dann bist Du sicher und hast Deine Ruhe". Das stimmt halt auf den verwundbaren Systemen nicht mehr. 32000 Schlüssel sind genauso gut auszuprobieren wie 32000 Passwörter. Und brute-force-Ausprobierer mit ein paar Tausend Versuchen sind nicht selten.
Mal sehn, wann die ersten im Logfile auftauchen, ich glaub ich schau da die nächsten Tage intensiver drüber...
Bei den Passwortausprobierern gibts hier übrigens auch einen Trend hin zu breiter gestreuten und langsameren Angriffen. Statt einer IP-Adresse, die innerhalb weniger Minuten massig ausprobiert, kommen jetzt tröpfchenweise im Minutentakt die Anfragen. Anscheinend zentral gesteuert, sämtliche Teilnehmer des Botnetzes arbeiten sich systematisch durchs Alphabet: Einer probiert den Usernamen "barrett", der nächste "brittney", der dritte "cale". Die Standorte der Botnetz-Mitspieler decken dabei so ziemlich den von Computern bewohnten Teil der Erde ab:
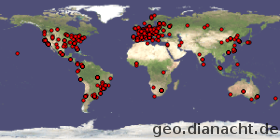
(die Karte zeigt die missglückten ssh-Anmeldungen auf diesem Server der letzten 3 Tage, unabhängig davon, ob das ein einzelner Versuch, ein brute force oder ein Vertipper von mir war)
Link gefunden bei Fefe
Tuesday, 13. May 2008
Grosser Schlüsseltausch
Saturday, 19. April 2008
Türkische Peaks

Die Clients und der Traffic
Besonders überrascht hat mich die hohe Anzahl verschiedener Clients. 242634 verschiedene IP-Adressen schlugen beim Server auf, ein paar Clients werden sicher mehrfach gezählt, weil sie sich unter verschiedenen IP-Adressen melden, aber allzu gross sollte der Fehler bei einem Tag Messzeit nicht sein.
Eigentlich hatte ich mit ein paar Tausend Nutzern gerechnet. Anscheinend ist das pool.ntp.org-Projekt doch beliebter als ich dachte. Der Server ist zwar auch bei der Liste der öffentlichen Stratum-2-Server gelistet, aber ich denke, die werden eher wenige Leute verwenden. Der Traffic von ca. 10 GByte/Monat ist jedenfalls seit der Eintragung dort nicht merklich gestiegen.
Die Verteilung der Häufigkeit ist interessant:
- 30% der Clients haben nur einmal gefragt
- 84% der Clients haben weniger als 6 Pakete verschickt
- 98% der Clients haben maximal 1x/Stunde zugegriffen
Diese hohe Anzahl der Wenignutzer wundert mich ein bisschen. Üblicherweise greifen andere ntp-Server im 1024-Sekunden-Takt zu. Nur die "einfacheren" Systeme zur Synchronisation wie "ntpdate" oder der Client von Windows synchronisieren sich seltener. Anscheinend verwenden doch ziemlich viele die einfachen Systeme statt sich mit einem ntpd zu beschäftigen. Hat ja auch Sinn, ein Rechner ohne besondere Anforderungen sollte mit 1 Synchronisation pro Tag oder pro Woche gut über die Runden kommen, so schlecht sind die eingebauten Uhren schliesslich auch nicht und ein paar Sekunden Abweichung sollte kaum jemand merken. Vielleicht sind viele Clients auch nicht mal echte Rechner, sondern irgendwelche DSL-Router, die sich bei jeder Einwahl mal die Zeit abholen.
Am oberen Ende sieht es grausam aus. Hier dominieren einige wenige Rechner, die völlig sinnlos Anfragen durch die Welt schicken und sich im Minutentakt synchronisieren. Das oberste halbe Prozent der Vielnutzer macht 30% des Traffics aus, 6% verbraucht allein der Spitzenreiter, ein Rechner der Humboldt-Universität zu Berlin, wo sie anscheinend sehr schlechte Rechneruhren sehr häufig synchronisieren müssen. Das ganze sieht nach einem NAT-Gateway für viele Uni-Rechner aus, weshalb auch meine automatische Aussperrung aufdringlicher Clients nicht hinhaut. Möglicherweise verhindert dieses Gateway sogar die Antworten des Servers und die Leute dort profitieren garnicht von ihrer Hartnäckigkeit.
Die Aufschlüsselung nach Ländern ist eher langweilig. Drei Länder bekommen 95% des Traffics ab, der Rest verteilt sich gleichmässig auf die ganze Welt.
- 46% des Verkehrs geht nach Deutschland
- 45% geht in die Türkei
- 4% nach Grossbritanien
Der grosse Anteil deutscher Clients war zu erwarten. Man sucht sich ja wegen der Paketlaufzeit gezielt möglichst nahe Server zur Synchronisation aus, der Pool ist auch "national" organisiert und liefert z.B. unter de.pool.ntp.org eine Liste deutscher Zeitserver aus und unter europe.pool.ntp.org eine Liste europäischer.
Die türkischen Clients überraschen auch nicht gross. Die Türk Telekom verkauft anscheinend DSL-Modems oder Router an ihre Kunden, die auf europe.pool.ntp.org voreingestellt sind. Auf diese Weise spart sich dieser Provider einen eigenen Server für seine Kunden und lässt den Pool für sich arbeiten.
Die Peaks
Eigentlich ist die Lastverteilung im Pool gerecht geregelt. Jede Anfrage nach "europe.pool.ntp.org" wird mit einem anderen Satz von 5 IP-Adressen beantwortet, die der Nameserver des Pools aus seiner Liste nimmt. Allerdings fragen die Clients nicht den Nameserver des Pools, sondern einen der Nameserver ihres Providers, der die Frage weitervermittelt und die Antwort für einige Zeit speichert und innerhalb dieser Zeit nicht erneut nachfragt. Die Gültigkeitsdauer der Antwort bestimmt der Poolnamesever, zur Zeit sind dort 20 Minuten eingestellt. Aus Sicht des Poolnameservers ist das vernünftig, er hält sich so die vielen Clients vom Leib und lässt die Nameserver der Provider arbeiten. Genau dafür ist diese Gültigkeitsdauer im Nameservice auch gedacht.
Aus Sicht der 5 einzelnen ntp-Server bedeutet das, dass sie für 20 Minuten die einzig zuständigen Zeitserver für ganz viele Clients eines Providers sind. Falls der Provider nur einen Nameserver hat, müssen sie sogar ganz allein sämtliche Kunden dieses Providers bedienen. Bei Langzeitnutzern als Clients würde das auch nichts machen, die fragen einmal beim booten nach und bleiben dann bei einem bestimmten Server. Die überwiegende Anzahl der "Einmalsynchronisierer" kommt aber dabei als Peak auf diese fünf Server zu.
Bei Kunden normaler Provider fallen diese Lastspitzen fast nicht auf, es kommen ja nicht alle Nameserver aller Provider gleichzeitig auf die Idee, ausgerechnet unseren Zeitserver zu speichern. Lediglich t-online und deutsche Telekom sind überhaupt in der Verteilung der Last zu sehen, weil der magentane Riese für 10% aller deutschen Kunden steht. Ich hab die Zuordnung zum Provider anhand des DNS gemacht, Clients mit eigenem Eintrag in den Nameserver werden also nicht zugeordnet. Viele der Kunden "sonstiger" Provider dürften also in Wirklichkeit zu einem der grossen Provider gehören, so erkläre ich mir jedenfalls die hohe Korrelation "Sonstiger" Provider mit der T-Firma.
Die Türken dagegen scheinen für DSL-Leitungen ein recht starkes Monopol der Türk Telekom zu haben. Und so werden auf einen Schlag die Hälfte aller türkischen DSL-Modems an unseren ntp-Server verwiesen. Die Auswertung der Peaks in den frühen Morgenstunden zeigt recht deutlich die geringen Schwankungen bei den anderen Providern im Vergleich zu den Clients der Türk Telekom.

"Kleinprovider" wie Arcor und Alice haben ebenfalls ihre Spitzenzeiten, die gehen allerdings in der Masse ihres grossen Konkurrenten unter. Ihre Peaks bestehen aus einer handvoll Clients mit ein paar Paketen pro Minute:

Wirklich hoch werden die Berge, wenn zufällig mehrere Nameserver der Türk Telekom auf einen einzelnen ntp-Server zeigen. der Berg um 12 lässt sich jedenfall ganz gut mit einem Nameserver für die erste halbe Stunde und einem zusätzlichen Nameserver für den Rest der Zeit erklären (Einheit der y-Achse ist bei diesen Diagrammen übrigens Pakete/Zehntelstunde)

Das Problem
Wenn man den Traffic allein betrachtet, sollten die türkischen Peaks kein allzu grosses Problem darstellen, ich schreibe hier ja nur über ein paar kByte/s, also keine wirklich interessante Datenmenge. Selbst in Peaks habe ich noch nie über 20 oder 30kByte/s beobachtet. Im Vergleich zum Webserver hier ist das eher wenig, zumal dort die Besucher wesentlich unregelmässiger kommen.
Was aber wirklich ein Problem darstellt ist die grosse Anzahl der Clients. Viele ntp-Server hängen hinter Routern und Firewalls, die in irgendeiner Form speichern, welche Verbindungen gerade aktiv sind, und haben nur begrenzt Platz in ihrer Tabelle offener Verbindungen. Das wäre zwar in vielen Fällen nicht nötig, im Falle von ntp, das das udp-Protokoll verwendet, schon fast unsinnig, wird aber trotzdem so gemacht. In manchen Fällen kann man das auch auschalten, in manchen auch nicht, weil die Firewall einfach an dieser Stelle nicht konfiguriert werden kann oder der Betreuer derselben über die Anzahl der zulässigen Verbindungen nicht diskutieren möchte.
Rechner hinter Firewalls mit knapp bemessenem Tabellenplatz für offene Verbindungen kommen also als Zeitserver für europe.pool.ntp.org nicht in Frage. Sobald deren Tabelle mit z.B. 8000 oder 16000 Verbindungen vollgelaufen ist, stellen die den Betrieb auf allen Internetprotokollen ein und warten erstmal ab. Das stört natürlich ungemein, wenn man die Kiste in erster Linie als Web/Mail/Fileserver betreiben möchte und Zeitservice nur ein Nebenjob ist. Folgerndes Bild zeigt die Anzahl der Verbindungen, die blaue Linie steht für das udp-Protokoll.

Die Lösung
Aus meiner Sicht gibt es keine. Die Türken von unserem Server aussperren ist gemein. Schliesslich ist der einzelne Kunde eines fiesen Providers nicht schuld. Allen Kunden der Türk Telekom die falsche Zeit zu liefern würde gehen, gilt aber als unehrenhaft. So bliebe nur den Nameserver des Providers abzuweisen oder die eigentlich vorgeschriebene Lösung für Firmen, die den Pool nutzen wollen: Speziell für ihn die IP-Adresse eines speziellen Zeitserver als Antwort zu schicken. Der darf dann auch gern in Ankara oder Istanbul stehen.
Für eine freundliche Lösung, die die Kunden nicht im Regen stehen lässt, bräuchte man aber Kontakt zu diesem Provider. Das haben auch schon ein paar Leute aus dem Pool probiert, aber der scheint recht unzugänglich zu sein. Möglicherweise scheitert es auch nur an den mangelnden Sprachkenntnissen.